有人遇到站点突然访问变慢或直接失败,直觉往往指向服务器故障,切回源站、重启服务、清缓存一通操作,结果仍旧无解。真正的症结常在网络路径与解析环节:不同地区用户反馈差异巨大,部分运营商能打开,另一些完全超时;同一机器用直连IP访问一切正常,换成域名却被重定向到陌生页面;DNS解析结果在短时间内来回变化,TTL异常地高或低。这些细节是快速判断的起点,抓住它们能在几分钟内分辨出是本地配置问题,还是更广泛的解析污染或访问受限。
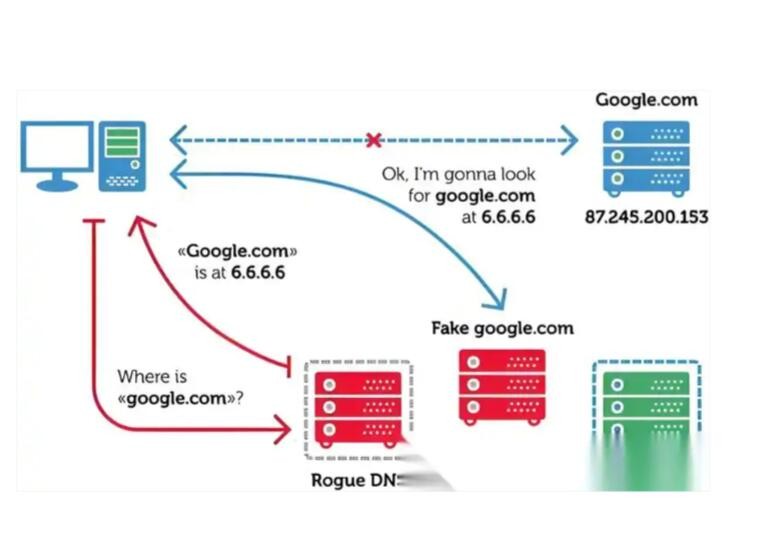
落地到操作层面,先做对照测试最有效。选取多地网络环境,比较同一主域与关键子域的解析出记录,分别询问本地递归与权威DNS,查看返回的A/AAAA是否一致、是否出现非预期自治域的IP段,记录TTL与生效时间。如果发现仅某些线路解析到陌生地址,或同一名称出现多组矛盾答案,基本可以判定存在污染或劫持。随后用HTTP与HTTPS分别发起请求,带上明确的Host与SNI,观察返回头与证书颁发者,若证书与预期不符、响应头出现非业务指纹或被异常301跳转,引导到无关联页面,风险更高。与之配套的还有直连源站IP测试,若源站服务健康而域名访问失败,说明问题多在解析或中间路径。
很多团队会把这类排查做成脚本化流程,结合多运营商探测节点与时序采样,形成高精度域名检测。通过不同自治域发起DNS查询,统计答复分布与延迟,辅以TCP/QUIC握手成功率和丢包率,能迅速圈定异常发生的层级。类似dnsjs的轻量脚本有助于批量对比结果,把一天内的波动绘成曲线,识别短时干扰与持续性阻断的区别。
当定位基本明确,如何降低影响就成了重点。业务层面可以准备备用域名与灰度切换策略,在监测触发后自动下发新解析,依靠低TTL加快生效;智能DNS按运营商与地域返回差异化记录,让仍可访问的用户持续服务;CDN与Anycast在多入口分发请求,缩短到达路径,提高穿越复杂网络的成功率。传输层的稳健也很关键,持续启用HTTPS与严格的HSTS,减少中间人篡改空间;评估新的SNI加密方案,降低名称暴露带来的风险。源站与解析策略要尽量收敛外部暴露面,避免不必要的泛解析与冗余子域,减少被动面。
修复层面的动作需要谨慎执行。发现解析污染时,先核验权威DNS上的配置与变更历史,再逐步调整记录指向,避免一次性大幅迁移造成新的不一致;对异常重定向要同时检查应用、CDN与WAF规则,清理缓存并比对日志,确认非业务逻辑导致的跳转。建立持续监控与告警体系非常必要,异常分布、失败率、握手错误类型都值得纳入指标;每一次处置应有复盘,更新检测脚本与切流预案。
还要避免一些常见误区。只在办公室网络测试难以还原真实情况,公共DNS的单点查询也可能被局部干扰误导;忽略IPv6使得一半问题藏在看不见的栈里;子域与泛解析往往被忽视,实际却是业务入口;证书链与OCSP异常可能被误判为应用错误。将这些环节纳入日常巡检清单,配合分环境演练,才能把故障从“突然压顶”变成“可控波动”。
真正的效率来自事前准备与事中证据。有了可复用的比对方法、跨网络的探测视角、可回滚的解析与路由策略,就能在判断是否被墙时更快、更准,同时把风险控制在对用户最友好的范围内。业务连续性与数据完整性始终是第一要务,检测与规避不过是保障它们的手段。